1.1
INTRODUCTION TO DATA, DATABASE,
DATABASE SYSTEM, DBMS
Data
Any raw fact or figure related to a person or something.
Maynothavesignificant meaning by itself.
Can be in any form, such as letters, numbers, words, images, audios or videos.
source of information.
For example: RAM, 20.
Information
Processed data or organized collection of related data that has significant meaning.
gives meaningful information.
can be used as data for further processing.
helps to make correct decisions.
For example: RAM is 20 years old boy
Database
A collection of data or information related to somebody or something on any subject or purpose.
can retrieve a variety of information from databases.
can be managed manually or by using suitable software on a computer.
Telephone directory, mark ledger, attendance register, flight schedule, library catalogue, census, encyclopedia, dictionary, log book, etc. are some examples of databases
Database Management System (DBMS)
A system or mechanism that manages databases.
an application software that stores, modifies, updates, and organizes databases and retrieves information from them.
MS-ACCESS, ORACLE, DBASE, FOXPRO, SYBASE, SQL SERVER, PARADOX, SPSS, Clipper, IBM Db2, etc
1.2
FIELD, RECORD, OBJECTS, PRIMARY KEY,
ALTERNATE KEY, CANDIDATE KEY
RDBMS and Table
A Relational Database Management System (RDBMS) is the most commonly used type of DBMS.
It stores a database in multiple tables and allows a user to link the tables and retrieve records from the linked tables.
MS-Access, Oracle, and SQL Server are some examples of RDBMS.
A table is the primary building block of a database.
Atable is a container or structure that stores data in the form of rows and columns.
A table is also known as a relation.
A single table is used to store data for a specific purpose or subject.
FIELD
A column in a table, which stores a particular type or category of data is known as a field.
A field is also known as an attribute.
Each field has a field name or column (i.e. field) heading which describes what type of data it can store.
The field name is an identifier of a field.
RECORD
A record is composed of related fields in a row of a table that gives information about a person or thing.
A record is known as a tuple.
Each record in a table is identified by its primary key.
A table is composed of records.
Database Object
Database object is a data structure that is used to store or reference data.
Table, index, sequence, view, and synonym are database objects.
A Table is the basic unit of storage and is composed of rows and columns.
A View is a logical table based on a table or another view. A view does not have its own data. It is
just like a window through which the data in the tables can be viewed or changed. It logically
represents subsets of data from one or more tables. It is stored in a database in the form of a query.
A Sequence object is used to create a sequence in adatabase. It is created by a user and can be
shared by multiple users to generate unique integers. It is normally used to generate primary key values.
An Index object is used to create an index in a database. An index provides direct and fast access to rows in a table and improves the performance of queries.
Asynonym object is used to create a synonym (i.e. an alias or alternate name) for a table, view, sequence, or other objectin a database. Synonyms simplify complicated and lengthy names by providing short and user-friendly alternative names, which help users to access objects easily. Synonyms hide the identity of objects and make it harder for malicious programs to access them.
Keys in Database
A key in DBMS is a column or a set of columns that help to uniquely identify a row in a table.
Keys are also used to establish relationships between the different tables.
Primary key, candidate key, foreign key, composite key, alternate key, etc. are some keys that are used in databases.
Primary Key
PK is a field or a group of fields which has a unique value for each record.
PKidentifies each record in a table, i.e. to whom the record belongs.
The PK does not accept duplicate values for a field, and it does not allow a user to leave the field
blank (null). Since it does not contain duplicate data in a field, it helps to reduce data redundancy.
Theprimary key is also used for setting up relationships between tables.
Aprimary key may be chosen among the existing fields in a table, or a newfield can be created
specifically for this purpose.
Symbol numbers of students, registration numbers of students, account numbers, and receipt
numbers are some examples of primary key fields.
Linking Tables
You can retrieve information from the multiple tables only when they have relationships.
To link the tables, one table, i.e. master table, contributes the primary key and another table, i.e. \
child table, contributes a field (i.e. foreign key) that refers to the primary key of the master table.
Alternate key, Candidate key & Foreign key
Alternate key
Atable can have more than one field that can be used as a primary key. Among the multiple fields,
only one field can be chosen as a primary key. So, all the keys that can be used as primary keys are
called alternate keys.
Candidate key
Candidate keys are those attributes that uniquely identify rows in a table. The primary key of a table
is selected from one of the candidate keys. So, candidate keys have the same properties as the
primary keys. There can be more than one candidate key in a table.
Foreign key
Aforeign key is used to establish relationships between two tables. A foreign key will require each
value in a column or set of columns to match the primary key of the referential table. Foreign keys
help to maintain data and referential integrity. A foreign key can have duplicate data but cannot
have null data.
1.3 ADVANTAGES OF USING DBMS
The following are some of the advantages of using DBMS:
Easy and efficient data management.
Efficient retrieval of a variety of information.
Reduces Data Redundancy.
Enforces data integrity.
Provides a data security facility.
Provides a data sharing facility.
Provides data backup and recovery.
Maintains Data consistency (i.e. uniformity).
Disadvantage of Database management system
The cost of hardware and software for a DBMS is quite high, which increases the budget of an
organization.
Most database management systems are often complex systems. So training for users to use the
DBMS is required.
In some organizations, all data is integrated into a single database, which can be damaged because
of the electric failure or problem with the storage media.
Use of the same program at the same time by many users can sometimes lead to the loss of some
data.
DBMS cannot perform sophisticated calculations.
1.4 Database Language
Database languages are used to interact with the database management system.
The database language contains the set of statements used to define and manipulate databases.
The two database languages are DDL (Data Definition Language) and DML (Data Manipulation Language).
Data Definition Language
The DDL defines data structures.
It is used for creating and altering tables, views, indexes, and columns within the database.
It is also used for linking tables and setting integrity constraints on the tables.
Some of the commonly used DDL statements are: Create, Alter, Drop, Rename, Truncate, and
Comment.
CREATE Statement
creates a new database or object, such as a table, index,
column, etc. in the database.
Syntax:
CREATE TABLE
(
Field_name_1 Field_type(width) [constraint],
Field_name_2 Field_type (width) [constraint],
…………….………………
Field_name_n Field_type (width) [constraint],
);
Where, Constrant may be PRIMARY KEY, NOT NULL or CHECK.
CREATE Statement
For example:
CREATE TABLE Student (Student Id INTEGER PRIMARY KEY, first name CHAR (15), Last name CHAR (15));
It creates a table named ‘Student’ with Student ID, first name and Last name as the fields with Student ID as Primary key.
ALTER Statement
reconstruct the data in the database.
allows to add new column, modify existing column, add
integrity constraints or drop integrity constraints.
Syntax:
ALTER TABLE <Table_name> [ ADD (COLUMN Type WIDTH);]
[ MODIFY (COLUMN Type WIDTH);
[ ADD PRIMARY KEY (Column_Name);]
For example,
ALTER TABLE Student ADD PRIMARY KEY (student_pk);
It sets Student_pk field of Student table as Primary key.
DROP Statement
deletes a table in the database or an entire
database.
Syntax:
DROP object_type object_name;
For example:
DROP TABLE Student;
It removes Student table from the database.
TRUNCATE Statement
• delete all the entries from the table.
Syntax:
For example:
TRUNCATE TABLE table_name;
TRUNCATE TABLE Employee;
It deletes all the data from the Employee table.
RENAME Statement
Syntax:
RENAME<Old_Table_name> TO <New_Table_name>
For example,
RENAME student To studentInfo
It changes name of student table as studentInfo.
Data Manipulation Language
The DML is used to access and manipulate data
in a database.
It allows a user to add or delete records, change
or update records, or move records from one
position to another.
Some of the commonly used DML statements
are select, insert, update, and delete.
Select Statement
retrieves specified record from the specified table in a database.
Syntax:
Select <Column_name> FROM <table_name> [WHERE<condition>];
For example:
Select * FROM student WHERE Firstname=”Purna”;
It displays all the records from the Student table where the first name is Purna.
Select * FROM student WHERE Firstname like '%k';
It displays all the records from the Student table where the first name ends
with a "k".
Select * From student WHERE Firstname like "a%";
It displays all the records from the student table where the first name starts
with 'a'.
DELETE Statement
deletes the records as specified condition.
Syntax:
DELETE FROM<Table_name>WHERE <condition>;
For example,
DELETE FROM studentinfo WHERE First name =”Pankaj”;
It deletes only those records from the ‘studentinfor’ table
where First name is ‘Pankaj’.
UPDATE Statement
modifies records as specified condition.
Syntax:
UPDATE <Table_name> [alias]
SET <column>=<expression>
{, <column>=<expression>}
[WHERE<condition>];
For example,
UPDATE studentinfo SET practicalMark=50
It changes practicalMark of each record to 50 .
Difference between DDL and DML
1.5 Database Model
Adatabase model is the logical design and structure of a
database that defines how data can be stored,
accessed, and updated in a DBMS.
It also defines the relationships and constraints applied to
the database.
Database models are used to support the development
of information systems by providing the definition and
format of data to be involved in future systems.
It also gives idea about possible alternatives to achieve
targeted solution.
ADBMSis built with a particular data model, but some of
the DBMS support multiple models.
Types of Database Models
Hierarchical model
Network model
Relational model
Hierarchical model
Developed by IBM and North American Rockwell in the 60s and 70s during
the mainframe computers era and known as Information Management
System.
Dataareorganized into a tree-like structure in top down approach.
Thehierarchy starts from the root data (i.e. root node), and then it expands
in the form of a tree, adding child nodes to the parent nodes.
Nowadays, this database model is used for storing file systems and
geographic information.
It is used in applications where high performance is required, such as
telecommunications and banking.
This model efficiently stores databases like index of a book, recipes,
sitemap of a website, windows Registry, etc. For example, the relationship
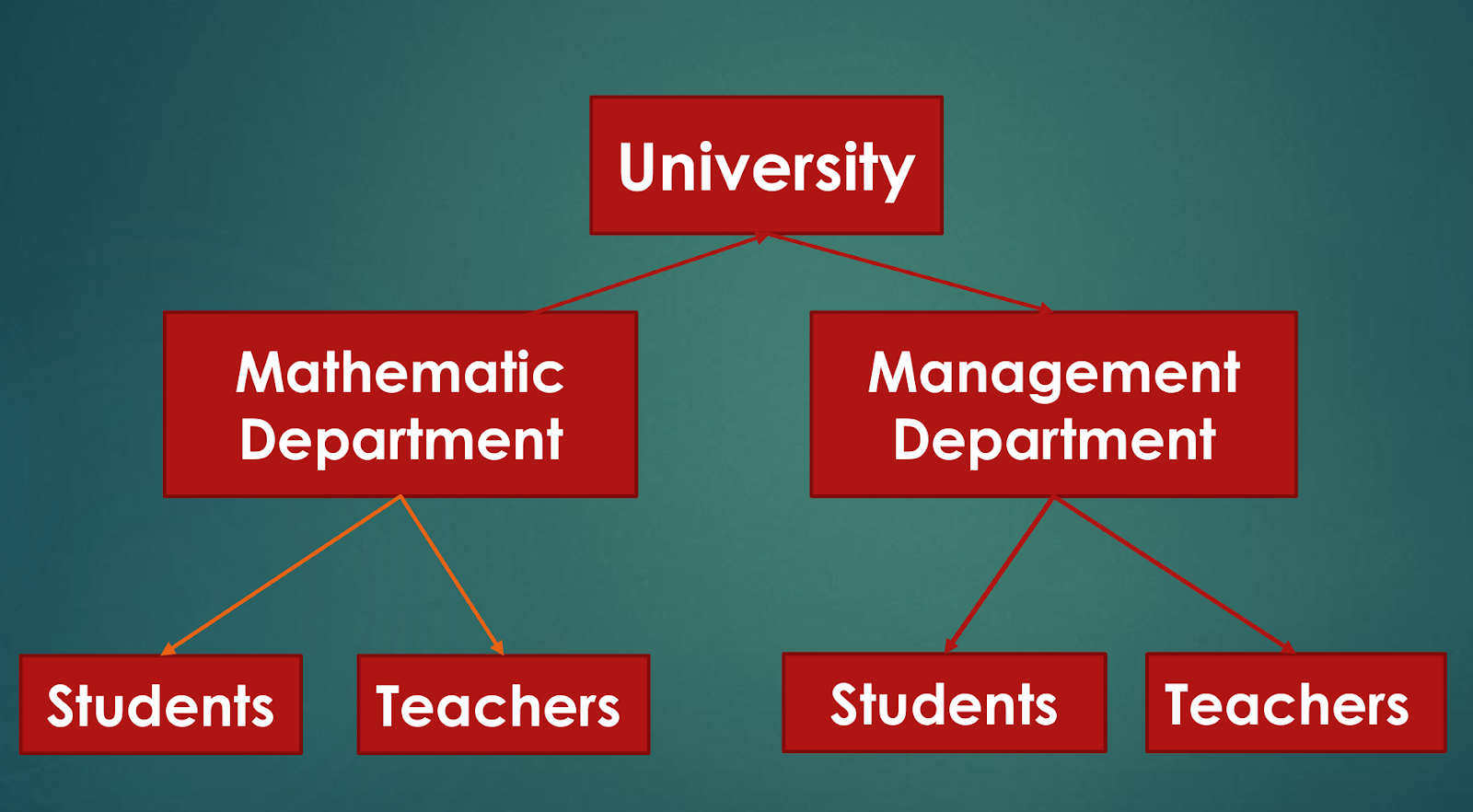
between teachers and students at a university can be represented as
given below:
Features of Hierarchical model
Each parent node can have many children
nodes.
Each child node has only one parent node.
This model represents one-to-many
relationships.
General Structure of Hierarchical Database
A hierarchical database consists of a collection of
records which are connected to one another through
links.
Arecord is a collection of fields, each of which contains
only one data value.
The schemafor a hierarchical database consists of
boxes, which correspond to record types
lines, which correspond to links
A parent may have an arrow pointing to a child, but a
child must have an arrow pointing to its parent.
Structure of Hierarchical Database
Example of Hierarchical database model Advantages of the hierarchical database
model
The model allows us to easily add and delete
information.
Data at the top of the hierarchy is very fast to access.
It supports one-to-many relationships.
It worked well with linear data storage mediums such as
tapes.
Any change in the parent node is automatically
reflected in the child node, so the integrity of the data is
maintained.
Disadvantages of the hierarchical
database model
Complex relationships are not supported.
Searching for data requires the DBMS to run through the
entire model from top to bottom until the required
information is found, making queries very slow.
Since it supports one child node with one parent node
only, when a child node needs to have two parent nodes
that cannot be represented using this model.
If a parent node is deleted, the child node will also be
automatically deleted.
Alternation in database structure is difficult to manage.
It does not support many-to-many relationships.
Network Database Model
It was invented by Charles Bachman in 1969.
It has a very similar structure as compared to the hierarchical model.
This model is the improvement over the hierarchical model.
It allows a many-to-many relationship in the tree-like structure. It means a child node can have multiple
parent nodes. The parent node is known as the owner and the child node is known as the member.
It is constructed with sets of related records.
Each set consists of one owner (i.e. parent) record and one or more member (i.e. child) records.
A record can be a member of multiple sets, allowing this model to convey complex relationships.
In this model, the records are connected to each other. In this manner, the hierarchy is maintained among
the records.
The data access in this database model is either in sequential form or can be in a circular linked list pattern.
And there can be multiple paths to access any particular record.
It contains redundancy among the records, which means one record can appear more than once in the
database model.
The below diagram of the network database model shows the many-to-many relationship. The members C3
and D2 each have multiple owners. The owners of D2 are C1 and C2. The owners of C3 are B1 and B2. In this
way, the network model can handle many-to-many relationships.
Structure of Network Model
The above diagram of the network database model shows the many-to-many
relationship. The members C3 and D2 each have multiple owners. The owners of D2 are
C1 and C2. The owners of C3 are B1 and B2. In this way, the network model can
handle many-to-many relationships.
Example of Network database
model

Advantages of Network Model
It supports many-to-many relationships.
It is more flexible than the hierarchical model.
It allows a user to set complex relationships.
Data can be accessed either in sequential form
or in a circular linked list pattern.
Since there are multiple paths to access the
particular record, the searching of record is fast.
Disadvantages of the Network
Model
It is more complex than the hierarchical
model. It is difficult to handle and maintain
a database in this model.
Data redundancy is higher in this network
model.
Relational model
It was introduced by E.F. Codd in 1970.
It is the most common database model.
In this model, data of a database are stored in tables in the form of rows and
columns.
Thetable in this model is known as a relation.
Arow in a relation is known as a tuple, which includes data about a specific
instance of the entity.
Acolumninatable isknown as an attribute.
Aparticular attribute or combination of attributes is chosen as a primary key
that can be referred to in other tables when it’s called a foreign key.
This model supports one-to-one, one-to-many, and many-to-many
relationships.
The relational database model uses Structured Query Language (SQL) to
perform operations on the database system.
Example of Relational Model
Advantages of Relational Database Model
It is simpler than the hierarchical and network models.
It is structural independence. The relational database is
only concerned with the data and not with structure.
It is a simple and easy to understand model.
It uses SQL to perform different operations on the
database.
The retrieval of data in this model is simple and easy.
It supports one-to-one, one-to-many, and many-to
manyrelationships.
The data integrity feature of this model helps to ensure
the accuracy and consistency of the data.
1.6 Normalization: 1NF, 2NF, 3NF
Database normalization is a technique of organizing the
data in a database to eliminate data redundancy and
ensure data integrity
Normalization can be defined as the multi-step process
that decomposes the larger table into smaller tables
and links them using relationships to remove duplicated
data and increases the clarity of data.
Since normalization removes the duplicated data, it
reduces the size of the database and increases the
performance.
It also helps in removing the insertion, update and
deletion anomalies.
Advantages of Normalization
It helps to eliminate or reduce data
redundancy.
It helps to maintain the data integrity.
It improves sorting and indexing operations.
It helps to remove insertion, update and deletion
anomalies.
It helps to make the data model more flexible
and save storage space.
It helps to improve the performance of the
database system.
Problems without Normalization
If the database is not normalized, there may be Insertion,
update and deletion anomalies in the database.
The insertion anomaly occurs when a user wants to insert
data into the database but the data is not completely or
correctly inserted into the target attributes.
The deletion anomaly occurs when a user wants to delete
data in the database but the data is not completely or
correctly deleted in the target attributes.
The update anomaly occurs when a user wants to
update data in the database but the data is not
completely or correctly updated in the target attributes.
Normalization Rule
In 1970, E. F. Codd formalized three rules for the relational
database model which are known as normalization rule.
In later years, three more normalization rules have been
added.
But the first three normalization rules are the most commonly
used.
The first three normalization rules formalized by E. F. Codd
are:
First Normal Form
Second Normal Form
Third Normal Form
First Normal Form (1NF)
It is the first step in the normalization process.
It is the most basic requirement to get started with the data
tables in the database.
It sets the fundamental rules for database normalization and
relates to a single table within a relational database system.
The purpose of the 1NF is to eliminate repeating groups of
attributes (i.e. fields) in an entity.
Rules of First Normalization Form
For a table to be in the first normal form, it should follow the
following rules:
There should not be repeated attributes of an entity.
There should not be repeated group of attributes. A repeating
group is an attribute that has more than one value in each
row of a table. It means each attribute should have atomic
values (i.e., values that cannot be further broken down).
Values stored in a column should be of the same domain. It
means the particular field should have the same type of data.
For example, the address field should contain the addresses of
the entity and no other values.
All the columns in a table should have unique names.
The values in the fields can be in any order.
How to correct violation of the 1NF
Identify the repeated groups or composited
attributes (which can be further broken down)
Create and name a new entity that describes
the repeated groups.
If there are multi-valued or composite attributes,
then create a new entity having only atomic
values.
Second Normal Form (2NF)
It is the second step in normalization process.
The purpose of 2NF is to eliminate partial
dependencies on primary keys.
Each non-key attribute in an entity must depend on
the primary key, not just a part of it.
2NF helps to remove data redundancy.
Partial dependency is a type of functional
dependency that occurs when non-prime attributes
are partially dependent on part of candidate keys.
Rules of Second Normalization Form
It should be in the first normal form.
It should have no partial dependency.
That means the table should not contain
any non-prime attribute depending upon
any candidate key.
How to correct a violation of 2NF
Create a new entity for the attributes that
depend on only part of the primary key.
Move the partially dependent attributes to the
new entity
Create an identifying relationship between the
new entity and the entity that had the violation.

Third Normal Form (3NF)
It is the third step in the normalization process.
It is very similar to the 2NF except that it deals with
entity with dependencies that does not involve the
key.
It also helps to eliminate data redundancy by
eliminating interdependencies between non-key
attributes.
It makes the database more reliable and easier to
update.
Rules for 3NF
A table is said to be in the third normal form when,
It is in the second normal form.
It doesn't have transitive dependency.
Transitive Dependency
It occurs due to an indirect relationship within the attributes
when a non-prime attribute has a functional dependency
on a prime attribute.
Let’s suppose ‘A’ is functionally dependent on ‘B’, and ‘B’
is functionally dependent on ‘C’. In this case, ‘C’ is
transitively dependent on ‘A’ through ‘B’.
How to correct a violation of 3NF
Create a new entity that contains all of the non
key attributes that depend on each other.
For the new entity, choose or create a primary
key, then create a non-identifying relationship
back to the original entity.
1.7 Centralized Vs. Distributed Database
Centralized Database
Adatabase that is stored, managed, and
manipulated at a single location on a
single computer.
It is used by mainframe computers, servers
and powerful desktop computers.
It is accessed by end-users through
terminals (in case of mainframe), computer
networks, or the Internet.
It is mainly used by institutions or
organizations.
The central library of a university is an
example of a centralized database which
can be accessed by each library in a
college.
Advantages of the centralized database
Since all data is stored at a single location, it is easier to access and
manipulate data.
Theresults of the data update are immediately available to the end-users.
It provides easier database administration.
There is a high level of data integrity in the centralized database.
Since high security measures are applied to the centralized database
system, the centralized database is more secure.
Since there is a single database file used at one location in the centralized
database, making backup copy is easier in this type of database system.
The centralized database has very minimal data redundancy since all
data is stored in a single place.
The centralized database consumes less power and requires less
maintenance, so it is cost effective.
Disadvantages of the centralized database
There is high data traffic in a centralized
database if there are more end-users.
The failure of a centralized system affects the
entire end-users.
If any kind of system failure occurs at the
centralized system, then the entire database will
be destroyed.
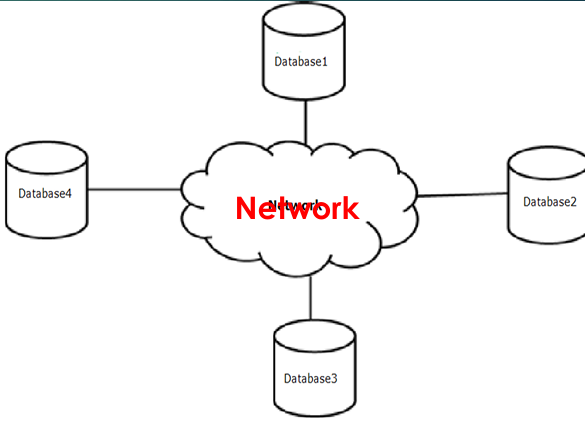
Distributed Database
It is a collection of multiple interrelated
databases located in different locations
on different computers.
It is a database in which data are
distributed or stored on multiple computers
located in different locations.
Inadistributed database, the databases in
different locations are connected through
the computer network, and they appear
as asingle database to the users.
Advantages of Distributed Database
This database can be easily expanded as the data is already spread
across different physical locations.
The databases at different locations can be managed individually.
Multiple users can access and manipulate the database simultaneously.
The distributed database can easily be accessed from different
networks.
This database is more secure in comparison to a centralized database.
The failure of a component does not fail the entire distributed system; it
just reduces performance. So, it is more reliable.
It provides a faster response to users since the individual computer can
process the queries of the users.
Disadvantages of Distributed Database
This database is very costly.
It is difficult to maintain because of its
complexity.
In this database, it is difficult to provide a uniform
view to users since it is spread across different
physical locations.
There may be the problem of data integrity.
Difference between Centralized database and Distributed
database

















Comments
Post a Comment